Rの様々な種類のグラフでデータの分布を理解する(hist、boxplot、stripchart)
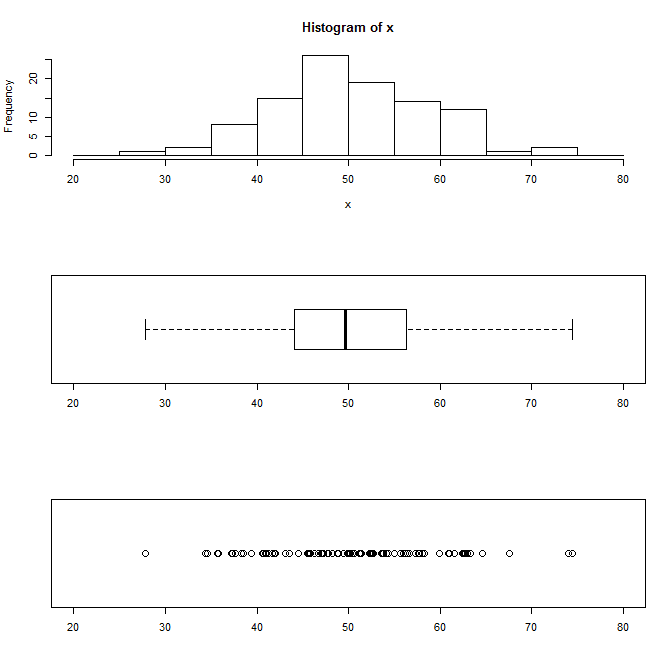
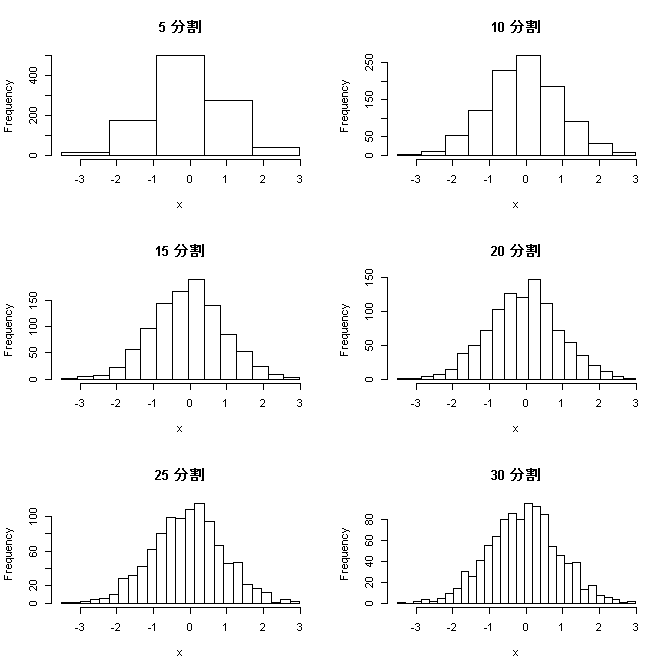
データがどんな感じで分布しているか見たいとき、とりあえず視覚化してみますよね。Rだと簡単だし。 で、どんな視覚化があるかというと、ヒストグラム(度数分布図)はお馴染みですが、その他にも、箱ひげ図や一次元散布図なんかがあります。 下記は、正規分布に従う100個のランダムデータを発生させ、同じデータをそれぞれのやり方で視覚化したものです。 x <- rnorm ( 100 , 50 , 10 ) # 正規分布に従うランダムデータ par ( mfcol= c ( 3 , 1 ) ) # 出力粋を3行×1列に分割 hist ( x , breaks= seq ( 20 , 80 , 5 ) ) # ヒストグラム boxplot ( x , horizontal=T , ylim= c ( 20 , 80 ) ) # 箱ひげ図 stripchart ( x , pch= 1 , cex= 1.5 , xlim= c ( 20 , 80 ) ) # 一次元散布図 ヒストグラムは学校でも習ったし、直感的にも分かりやすいですよね。度数が高さで表されているので、量的にも理解しやすい。 箱ひげ図の意味は、以下のようになっています。 ひげの左端 ・・・ 最小値 箱の左端 ・・・ 25%点 中央の太線 ・・・ 中央値(50%点) 箱の右端 ・・・ 75%点 ひげの左端 ・・・ 最大値 慣れないとピンとこないかもしれません。 一次元散布図は、データをそのまま座標にプロットした感じですね。データ数が多くなってくると、データの粗密はなんとなく分かりますが、数はよく分からなくなってしまいます。 こうやって並べてみると、ヒストグラムでいいじゃんって気もしますが、そうでない場合もあります。複数のデータを比較したいような場合は下の2つの方が使いやすい気がします。 ↓こんな感じで、標準偏差の異なる複数のデータを作ってみます。 > sd_05 <- rnorm(100,50, 5) > sd_10 <- rnorm(100,50,10) > sd_15 <- rnorm(100,50,15) ...